小米跟随DeepSeek调整大模型API定价,永久降价最高达99%。
- 新闻资讯
- 2026-05-27 16:27:02
- 1
小米紧跟DeepSeek,于5月27日宣布旗下MiMo-V2.5系列API实施永久性大幅降价,最高降幅达99%,核心模型“MiMo-V2.5-Pro”输入缓存命中价格降至每百万tokens 0.025元,性价比提升5至8倍,此举旨在吸引开发者与企业,并逐步引导用户向高性价比的V2.5核心系列迁移,此次价格风暴得益于算法优化与算力效率提升,标志着大模型商用门槛进一步降低。
在AI大模型赛道掀起新一轮“价格风暴”之际,小米在5月27日带来了令人瞩目的动作——正式宣布其MiMo-V2.5系列API实施永久性大幅降价,最高幅度达99%,紧随DeepSeek的“永久降价”后,这家科技巨头又在算力普惠上推出一记重量级举措,此举正迅速吸引着开发者和企业的目光。
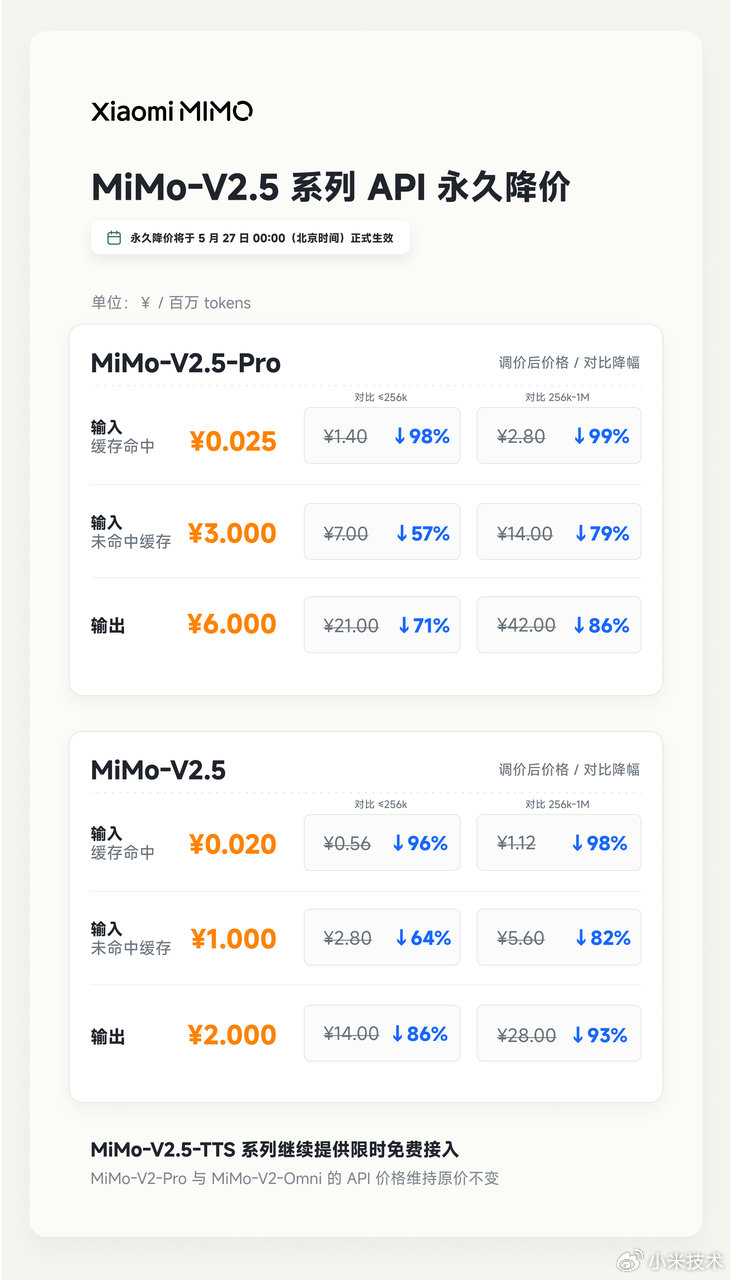
降价自发布当日起正式生效,相比传统按上下文窗口长度计费的方式,小米这次做了明显改变——不再区分不同长度下的费率和复杂度限制,新规还对“Token Plan”体系进行了优化升级,根据最新报价,用户在同等支付金额下,所获得的可用Token数量可提升至原来的5倍到8倍,意味着性价比显著增强,企业预算有望更灵活地用于更大规模的模型调用。
具体到数字表现,核心模型“MiMo-V2.5-Pro”可谓是降价凶猛,其“输入缓存命中”价格降至每百万tokens 0.025元,相比此前针对≤256k场景的价格1.40元整体下滑98%;与大窗口(256k-1M)原价2.80元相比,幅度更是逼近99%,而“输入未命中缓存”报价调整为每百万tokens 3.000元,对比原先“≤256k”的7.00元便宜了57%,若对标长窗口的原价14元则下降79%,输出端的定价定为6元/百万tokens,对照原先21元和42元的基准,分别下降了71%与86%。
另一主力型号“MiMo-V2.5”标准版在力度上也毫不逊色:输入缓存命中价为0.020元/百万tokens,较≤256k原价0.56元下滑96%;若对比256k-1M的原价1.12元,折扣力度达到98%,输入未命中缓存则以1.000元/百万tokens出售,较原生小规格的2.80元减少了64%,对比长窗口场景(5.60元)便宜了82%;输出端2元/百万tokens,呈现出分别达86%和93%的高位缩水。
为何聚焦核心模型,其他版本保持价格不变?
需要注意的是,此番降价主要锁定在MiMo-V2.5核心系列上。“MiMo-V2.5‑TTS”则仍旧施行限时免费接入政策,技术定位更拔尖的“MiMo-V2-Pro”与“MiMo-V2‑Omni”两款高阶模型的API价格将维持原状,没参与调降,特别是Token Plan套餐,不仅要退出新阵容,未来也即将下线,这种“双轨价格策略”传达的信号十分明确:小米决心将开发者们从高价复杂度高的线路,逐步引向核心竞争力更强、性价比更足的V2.5版系列。
罗福莉与MiMo的“青春化创新”
这一系列从策略到产品的推动,与背后的指挥官密不可分,主导MiMo大模型架构升级的核心人物是罗福莉——一位曾效力于DeepSeek的95后AI领军人才,2025年11月,罗福莉正式加盟小米,就此执掌MiMo研发脉络,从小米内部消息可知,雷军为使罗福莉加入团队,拿出了千万元年薪筹码,在她的统筹主导下,小米组建了一支“平均年龄只有25岁、清北毕业生比例超过六成”的生力军团。
正因如此,MiMo大模型才能迅速跑出多代创新节奏,今年3月,该公司一口气推出了“MiMo-V2-Pro”、“MiMo‑V2‑Omni”和“MiMo‑V2‑TTS”三大基础板块;随后迅速打磨出V2.5进阶版,补齐了高性能推理、轻交互和语音合成等一系列全场景能力,使其成为目前小米大模型方阵中最具商用普惠力的王牌梯队,可以说,雷军押注的是年轻、敏捷和算法深耕的结合,不只是简单降价取胜。
产品矩阵与布局逻辑
小米已初步搭好MiMo大模型完整矩阵:
• MiMo-V2.5‑Pro:“力量选手”,主打深层复杂推理,适合企业级智能体开发、关键业务分析和专业判断等高阶商用场景,这一分支的降幅最大,等于在使用高端算力成本的基础上,直接拉低选用门槛。
• MiMo-V2.5‑TTS:语音方向的关键入口,依然维持免费接盘路线,意在吸纳更多音频类开发者冲刺语音赛道的规模效应。
“MiMo-V2‑Pro”仍是队里的旗舰基底,发力万亿参数MoE架构的性能标杆。“MiMo-V2‑Omni”则专注全模态融合,行业适应性不停延展。

雷军的最新说法与600亿投资
在这波降价之前的那一天,雷军面对媒体表态时直接打出一张技术信心牌:“Xiaomi MiMo-V2.5-Pro现已排上Artificial Analysis榜单头部,综合智能指数、Agent指数国际开源模型,与友商并列第一。”他同时定下重磅目标:从今年开始,未来三年里小米将在AI这一体再次投放600亿元人民币。
跟进的序曲:从DeepSeek到K型分化
实质上,数天前开启首轮“永久降价”的并非只有小米,这家头部企业的举措,与DeepSeek降价动作密不可分——后者对旗下“DeepSeek-V4‑Pro”模型一直保持限时优惠转永久常规化的循环改制,大幅下调至原价四分之一的价位,5月31日期满后,对应API“一直价”将执行如下水平:输入缓存命中为0.025元/百万tokens、未命中缓存3元/百万tokens、输出6元/百万tokens,总计来看,相对先发价有75%的“划算”杀跌。
DeepSeek先前宣布杀入市场门类的最新V4模型于2026年4月底推出,拥有百万字超长上下文,同一实力范围中,Agent能力与多知识维度推理完成绝对开源于国内领先,DeepSeek-V4‑Flash 和 ‑Pro由此拿到低成本运营的用户心理对标地位,并间接为小米和其他同行演绎了永久降价样板工程里精准的成本转化逻辑,企业级用户乃至中小结算方对其高复用率的宽系统非常钟爱。
K型阵营:降价走量与高端溢价并存
纵观整个中国大模型价格竞速,可用“K型分化”作概括——即差异化路线初现端倪:阿里云通义千问悄悄将相关API单价再次朝下滑移,字节跳动豆包紧跟步伐拉向走量时代,与此对比,专功企业定制路的智谱GLM、腾讯混元,保持在持平基础上适度升格表达出从容溢价能力,虽然一场价格潮、胜似激烈砍价,但这一切里真相却另有奥义。
这一定价上的分可并不是简易的营销战术疲劳竞赛!它来自更底层的算法优化(意图节省tokens及机时边际)、推理引擎对算力的成倍提升,再加上硬件基础设施价格走低这一漫长整装合作结果。
AI聚合平台AI.cc近期发布的《2026年度大模型API基础设施报告》出具硬核依据:企业级大模型全年单体Token调用已疯跌明显重挫——与去年相比暴跌67%,开源部分占全量调用总量的38%,并稳定扩张,可以说性价比打在这条有纵深的技术核心韧带上,逐渐淬成铁腕竞争力。
毫无疑问,今天的用户调模型门槛比仅一年前肉眼可见便宜太多,技术上日进千里的进化、真实用户圈落地不断扩大,正在催促业内必须由浅层次的价格表态,转向长效的迭代市场构建。